Scrapling 是一个 Python 网页抓取框架,定位很清楚:从一次简单请求,到需要调度、会话管理、断点恢复的大规模 crawl,都尽量放在同一套工具链里处理。它不是只包装一个 HTTP client,而是把解析、抓取、浏览器自动化、stealth、spider 模板和 MCP server 这些能力放到一起。
截至 2026 年 5 月 20 日,这个 GitHub 仓库已经有约 51.3k Star、4.9k Fork,许可证是 BSD-3-Clause,最近一次 push 是 2026 年 5 月 18 日。最新 release 是 v0.4.8,发布时间是 2026 年 5 月 11 日,更新重点放在 LinkExtractor、CrawlSpider、CrawlRule 和 SitemapSpider 这些更适合规模化爬取的模块上。
比一次性抓页面更进一步
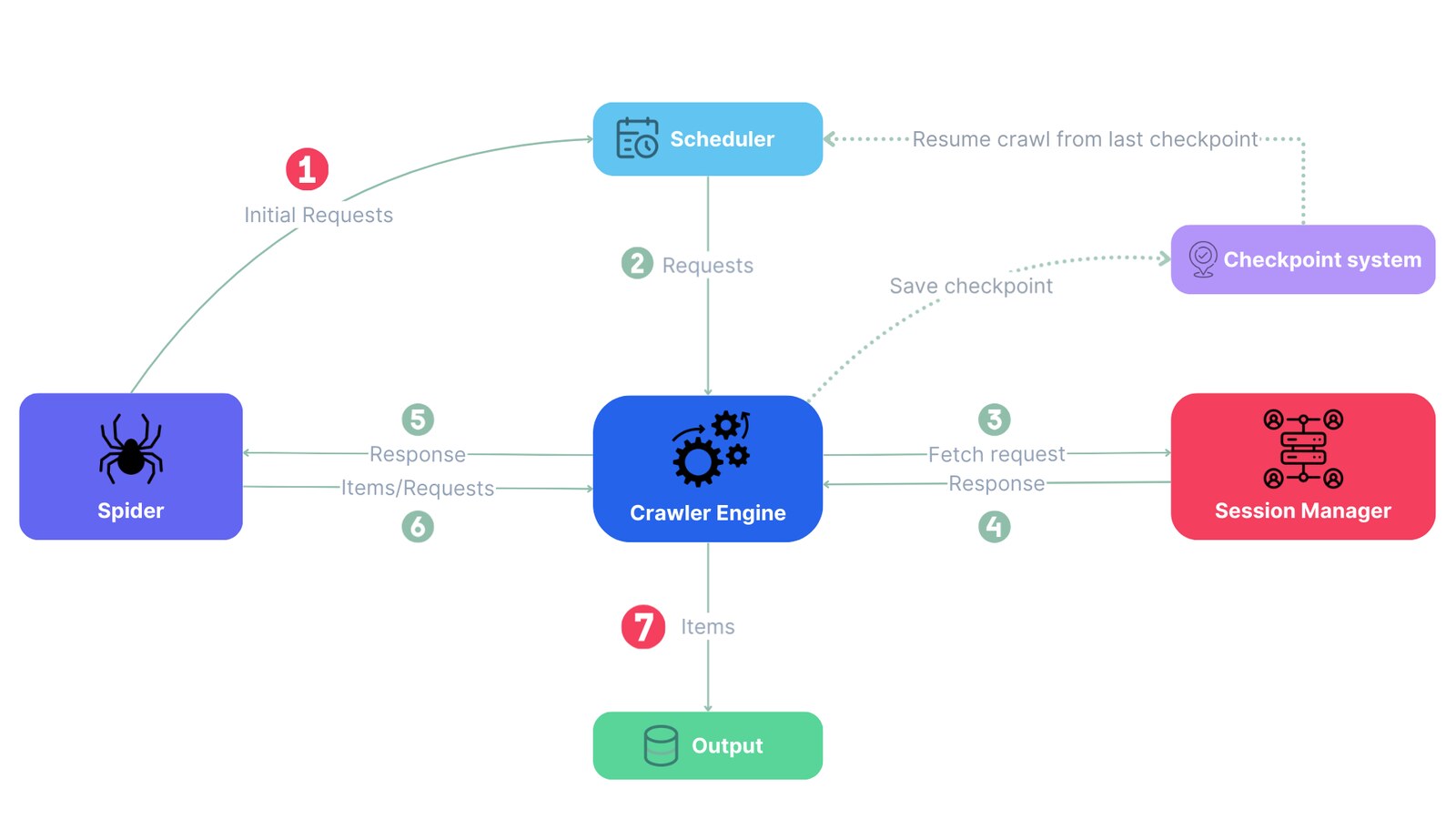
Scrapling 最有意思的地方,是它把“抓取页面”和“组织一次 crawl”分开看。单页数据提取时,你可以用类似现代解析库的选择器去拿字段;一旦任务变成跟链接、处理分页、从 sitemap 起步、保存 checkpoint、恢复上次爬取进度,它也有对应的 spider 架构来接住。
v0.4.8 里新增的 LinkExtractor 可以从 Response 中抽取 URL,并通过 allow、deny、domain 等规则控制链接范围;CrawlSpider 和 CrawlRule 则让你少写很多“匹配链接后继续跟进”的重复代码;SitemapSpider 可以直接从 sitemap 或 robots.txt 入口开始派发 URL。这些能力对做内容索引、竞品监测、搜索结果归档、数据集构建的人都很实用。
它还把 Playwright、stealth、selector、MCP server 等关键词放进了项目主题里。换句话说,Scrapling 不只是传统爬虫库,也在往 AI agent 和自动化数据获取场景靠:当模型或 agent 需要稳定拿网页数据时,能不能恢复、能不能适应页面变化、能不能把抓取流程结构化,都会变得很重要。
当然,网页抓取工具最终还是要回到合规和目标站策略上:robots、服务条款、访问频率、登录态和数据用途都需要自己判断。Scrapling 解决的是工程层面的抓取、解析和调度问题,不是帮你绕过所有边界。
项目地址
文档:https://scrapling.readthedocs.io/en/latest/
项目地址:https://github.com/D4Vinci/Scrapling
原创文章,如若转载,请注明出处:https://wefound.cc/p/3036.html