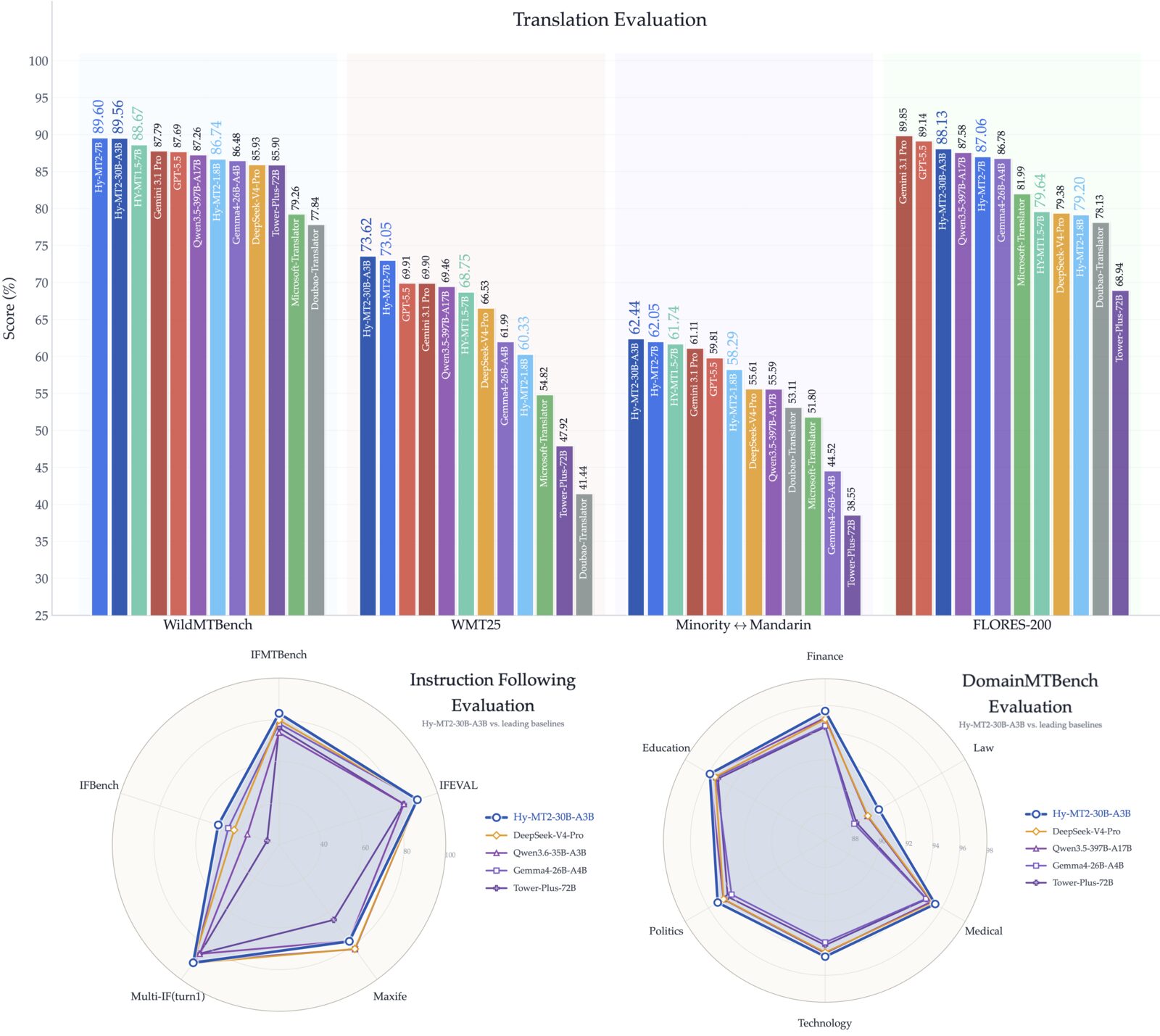
腾讯混元把新一代机器翻译模型 Hy-MT2 放了出来。它不是泛用聊天模型换个提示词做翻译,而是面向真实业务里的多语言翻译场景做的“快思考”模型家族:1.8B、7B 和 30B-A3B 三个尺寸,覆盖 33 种语言互译,也强调在多语言提示下遵循术语、风格、结构化数据等翻译指令。
这类模型最值得关注的地方,是它把“能跑得动”和“翻得稳”同时往前推了一步。README 里提到,配合 AngelSlim 1.25-bit 极端量化,1.8B 版本的存储需求可以压到 440MB,推理速度提升 1.5 倍。对需要离线翻译、端侧部署、私有化文档处理,或者想在本地服务里挂一个专门翻译模块的团队来说,这比单纯追求大模型参数规模更实用。
模型链路也比较完整。Hy-MT2 已经在 Hugging Face 和 ModelScope 提供多个权重版本,包括 1.8B、7B、30B-A3B,以及 FP8、GGUF、2bit / 1.25bit GGUF 等部署形态;官方 README 也给了 transformers、vLLM、SGLang 和 llama.cpp 的推理示例。需要注意的是,GGUF 方案依赖 llama.cpp 里的 STQ kernel PR,部署前要看清对应说明。
另一个有意思的点是 IFMTBench。腾讯这次同时开源了一个评估翻译指令遵循能力的 benchmark,不只看常规翻译分数,也把术语、风格、分隔符、结构化数据、上下文背景等实际工作中很容易出错的约束纳入评测。对做出海、本地化、字幕、客服知识库或多语内容生产的人来说,这比只看 BLEU 或排行榜数字更接近日常痛点。
不过它的授权不是常见的 MIT / Apache 这类宽松开源许可证,而是 Tencent HY Community License。README 和许可证文件都值得认真读一遍,尤其是商业使用、地域和可接受使用政策相关条款。如果只是研究、评测或搭一个内部翻译工作流,Hy-MT2 是一个很值得试的专用模型选择;如果要放进面向客户的产品里,则建议先把授权边界确认清楚。
项目地址
官网:https://aistudio.tencent.com/llm/zh?tabIndex=0
项目地址:https://github.com/Tencent-Hunyuan/Hy-MT2
原创文章,如若转载,请注明出处:https://wefound.cc/p/3181.html




