LLM Wiki 把 Karpathy 提出的 LLM Wiki 方法论做成了一个真正可用的跨平台桌面应用:你把文档、网页或文件夹丢进去,它让 LLM 先理解资料,再把内容整理成互相链接的 Wiki。和每次提问都重新检索、重新生成答案的传统 RAG 不一样,它更像是把知识“编译”成一套会持续维护的个人资料库。
这个项目现在在 GitHub 上已经有约 9,052 个 star,主语言是 TypeScript,应用基于 Tauri / React 构建,许可证是 GPLv3。它适合那些资料量很大、又不想只靠聊天记录堆上下文的人:论文、项目文档、研究笔记、业务资料,都可以进入同一个可追溯的知识空间。
把 RAG 变成会长期维护的 Wiki
LLM Wiki 的关键点是“增量维护”。摄入资料时,它先让 LLM 做结构化分析,再生成 Wiki 页面、实体页、概念页、索引和操作日志;源文件会用 SHA256 做增量缓存,未变化的内容不会反复消耗 token。每个生成页面还保留 sources 字段,方便你知道某个结论来自哪份原始资料。
这种方式对长期项目特别友好。你不是每次问问题才临时拼上下文,而是让系统持续把资料沉淀成 Obsidian 兼容的 Wiki,再用交叉链接、索引和摘要帮助 LLM 读懂你的知识库结构。
桌面应用里的知识工作台
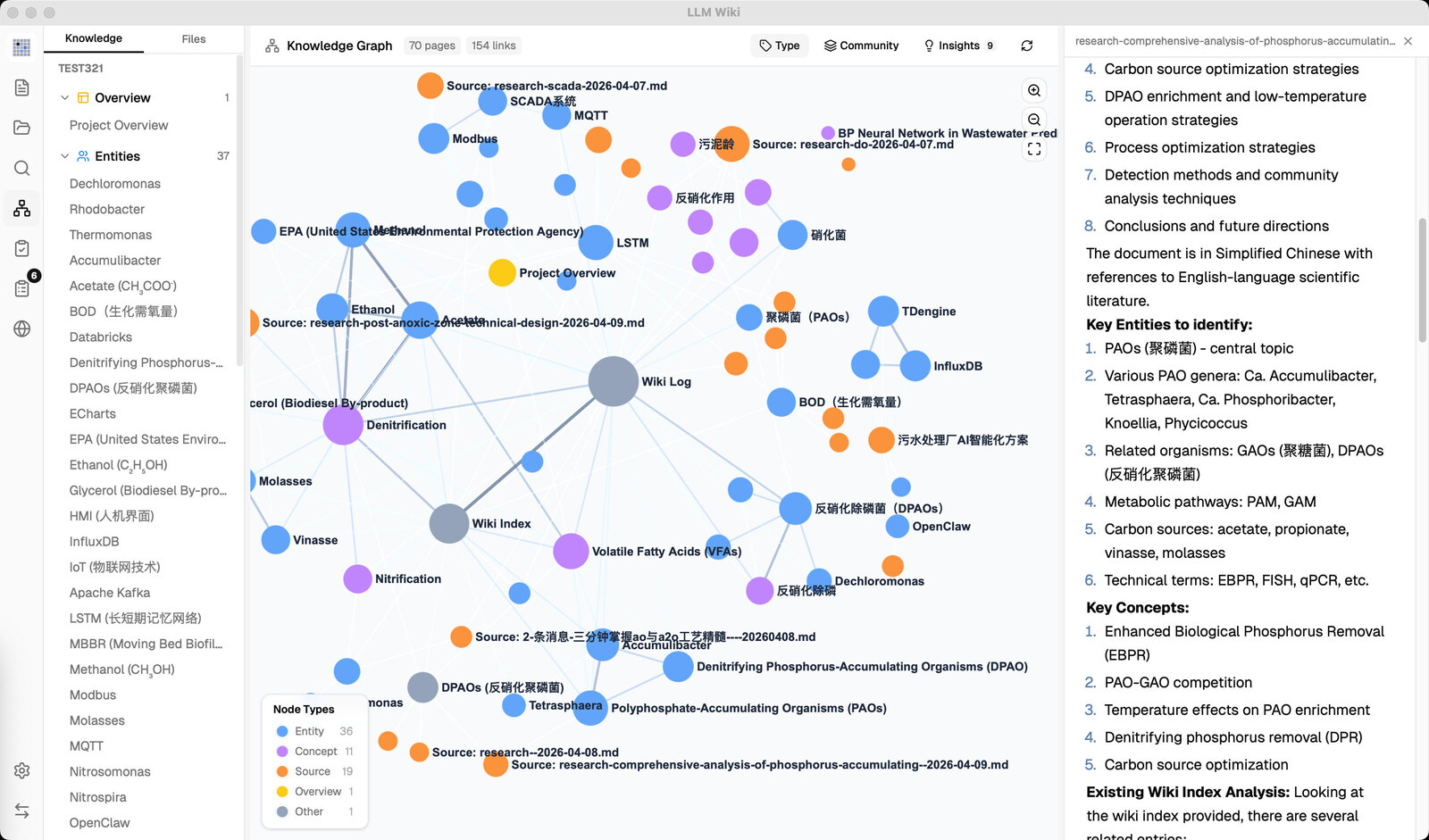
相比一份方法论文档,LLM Wiki 的实现更接近完整工作台:左侧是知识树和文件树,中间可以对话,右侧能预览页面;它还提供知识图谱、搜索、Lint、异步审核、Deep Research 和设置面板。图谱部分不只是可视化链接,还用直接链接、来源重叠、Adamic-Adar 和类型亲和四个信号计算页面相关性,并支持 Louvain 社区检测。
它还内置本地 HTTP API 和配套 agent skill,可以让 Claude Code / Codex 这类代理通过 token 鉴权访问本地知识库,执行混合搜索、读取文件、遍历图谱或重新扫描来源。对开发者来说,这一点很有意思:个人知识库不只给人看,也能成为 AI agent 的本地上下文层。
更适合愿意自己掌控资料的人
LLM Wiki 不是一个轻量网页收藏夹。它的价值在于把个人资料库当成长期系统来经营:文件夹递归导入、Source 目录自动监听、持久化摄入队列、失败重试、向量语义搜索、图谱洞察和一键 Deep Research 都围绕“长期维护”展开。
需要留意的是,项目仍然是开源桌面应用路线,安装、模型端点、搜索服务和本地配置都需要一定动手能力;GPLv3 也意味着你在二次分发和改造时要认真看许可证要求。但如果你一直想把散落的 PDF、网页、笔记和项目资料变成可查询、可追踪、可让 AI 继续工作的 Wiki,它已经把原本抽象的方法论推进到了可运行的软件形态。
传送门
https://github.com/nashsu/llm_wiki
原创文章,如若转载,请注明出处:https://wefound.cc/p/3493.html