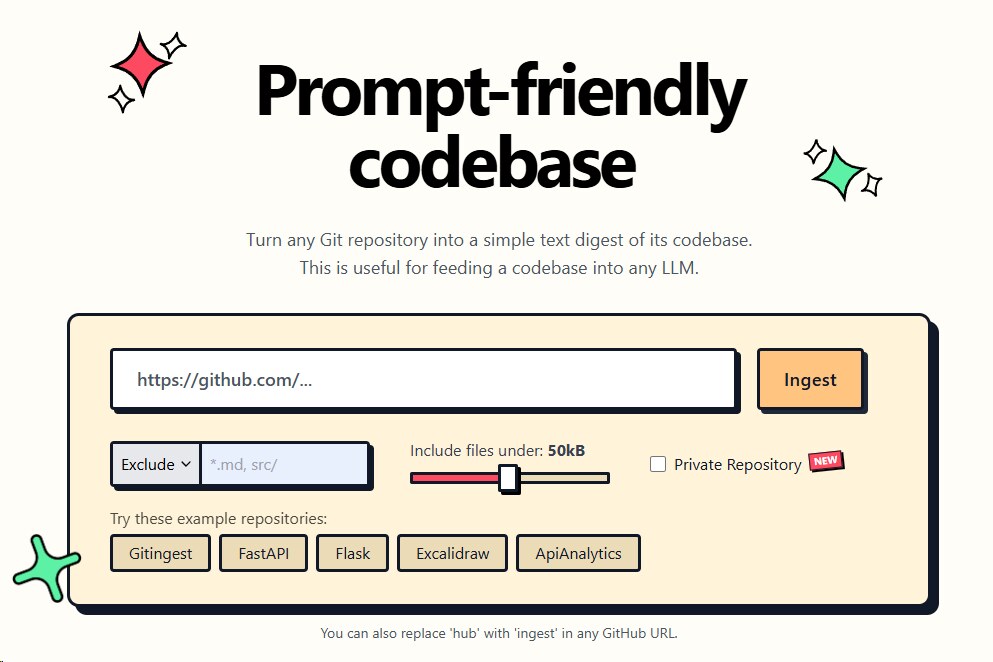
Gitingest 是一个把 Git 仓库整理成 LLM 友好文本摘要的工具。它最出圈的用法很简单:把 GitHub 链接里的 hub 换成 ingest,就能得到对应仓库的 digest。对经常把代码库喂给 ChatGPT、Claude 或本地模型的人来说,这相当于把“复制项目上下文”这件事做成了一个稳定入口。
这个项目当前在 GitHub 上有 14760 stars 和 1093 forks,主语言是 Python,许可证是 MIT。它不只是一个网页服务,也提供 CLI、Python 包、浏览器扩展和自托管方案;README 里还提到私有仓库可以通过 GitHub Personal Access Token 处理,输出里会包含文件树、摘要大小和 token count 这类对提示词准备很有用的信息。
Gitingest 的价值在于它把“代码仓库 → 模型上下文”中间那些烦人的清洗步骤收拢了。普通做法往往要手动挑文件、过滤依赖目录、控制 token、拼目录树;Gitingest 则把目录结构、文件内容和统计信息统一成 prompt-friendly digest,并默认遵循 .gitignore,减少把无关文件塞进上下文的概率。
如果你偏命令行,它可以通过 gitingest /path/to/directory 或仓库 URL 直接生成 digest;如果你在 Python 项目里做自动化分析,也可以调用 ingest 或 ingest_async。这让它既能作为一次性“把这个 repo 发给模型看看”的工具,也能嵌进代码审查、文档生成、迁移评估、RAG 预处理之类的工作流。
更适合团队使用的部分是自托管。项目提供 Docker 和 Docker Compose 方式,能够配置允许访问的域名、S3 存储、Prometheus metrics 和 Sentry 等环境变量。换句话说,如果团队不想把私有仓库内容丢给公共服务,可以把它部署在自己的环境里,再配合访问控制和内部模型使用。
它不是万能的代码理解工具,本质上仍然是在做“上下文打包”:仓库越大,越需要控制 include/exclude、文件大小上限和隐私边界。但正是这种朴素定位,让它在 AI 编程工作流里很实用。需要把一个项目快速变成可读、可贴、可检索的模型输入时,Gitingest 是一个很顺手的基础件。
项目地址
官网:https://gitingest.com
项目地址:https://github.com/coderamp-labs/gitingest
原创文章,如若转载,请注明出处:https://wefound.cc/p/3663.html