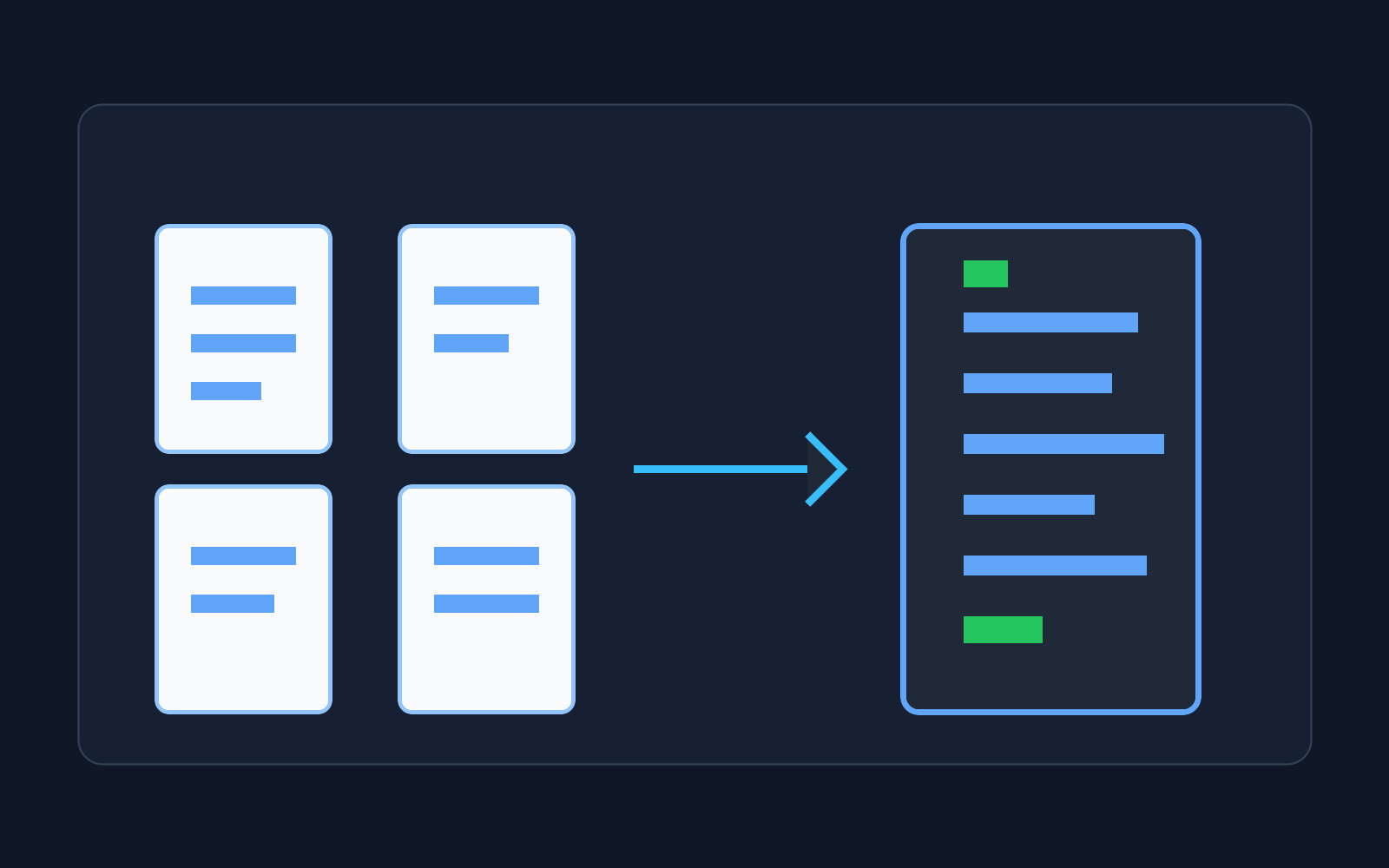
MarkItDown 是 Microsoft 开源的一个轻量级 Python 工具,目标很明确:把常见文件和网页内容转换成更适合 LLM、RAG、检索和文本分析使用的 Markdown。它不是那种追求像素级还原版式的文档转换器,而是更在意把标题、列表、表格、链接这些结构保留下来,让后续模型和脚本更容易处理。
这个定位很适合现在的知识库整理工作。PDF、Word、PowerPoint、Excel、HTML、CSV、JSON、XML、ZIP、EPub,甚至图片的 EXIF/OCR、音频的元数据和语音转写、YouTube 链接,都可以进入同一条转换链路。对于正在做内部资料问答、文档索引、客服知识库、研究资料清洗的人来说,少维护几套解析脚本,本身就是很实在的效率收益。
使用门槛也比较低。项目要求 Python 3.10+,常规安装可以直接用 pip install 'markitdown[all]',命令行里执行 markitdown path-to-file.pdf > document.md 就能把文件转成 Markdown;也可以在 Python 代码里调用,嵌进自己的数据处理流水线。
更像 LLM 前处理层,而不是排版转换器
MarkItDown 有一个值得注意的取舍:它把输出目标设在“让机器更容易读懂”,而不是“让人看到一份漂亮的复刻文档”。这意味着它适合放在导入、索引、摘要、问答、归档这些流程里,而不是替代专业的 PDF/Office 排版工具。项目目前在 GitHub 上已经有 129041 stars,采用 MIT License,对团队内部二次集成也比较友好。
如果需求更复杂,它还提供按需安装的可选依赖和插件机制。比如只装 Word、Excel、PDF、Outlook、YouTube 转写等对应能力,或者启用第三方插件;官方还提到 Azure Content Understanding、LLM Vision OCR 这类扩展路径,适合需要结构化字段抽取、多模态内容处理的场景。
需要提醒的是,任何文档解析工具在处理不可信文件时都应该放进受限环境里跑。尤其是批量处理外部上传文件、压缩包或办公文档时,最好用容器、低权限账户和隔离队列来做,别让解析进程直接拿到过高的系统权限。
传送门
https://github.com/microsoft/markitdown
原创文章,如若转载,请注明出处:https://wefound.cc/p/4136.html