supermemory 是一个面向 AI Agent 的记忆与上下文引擎,也可以作为个人或公司的“AI 大脑”来用。它把长期/短期记忆、用户画像、混合搜索、连接器和文件处理放进同一个上下文层,让 AI 不再只依赖当前会话。
项目以 TypeScript 为主,MIT 开源,仓库目前约 23.5k stars。官方 README 里把它定位为“Memory API for the AI era”,并强调在 LongMemEval、LoCoMo、ConvoMem 这些 AI memory benchmark 上拿到 #1。
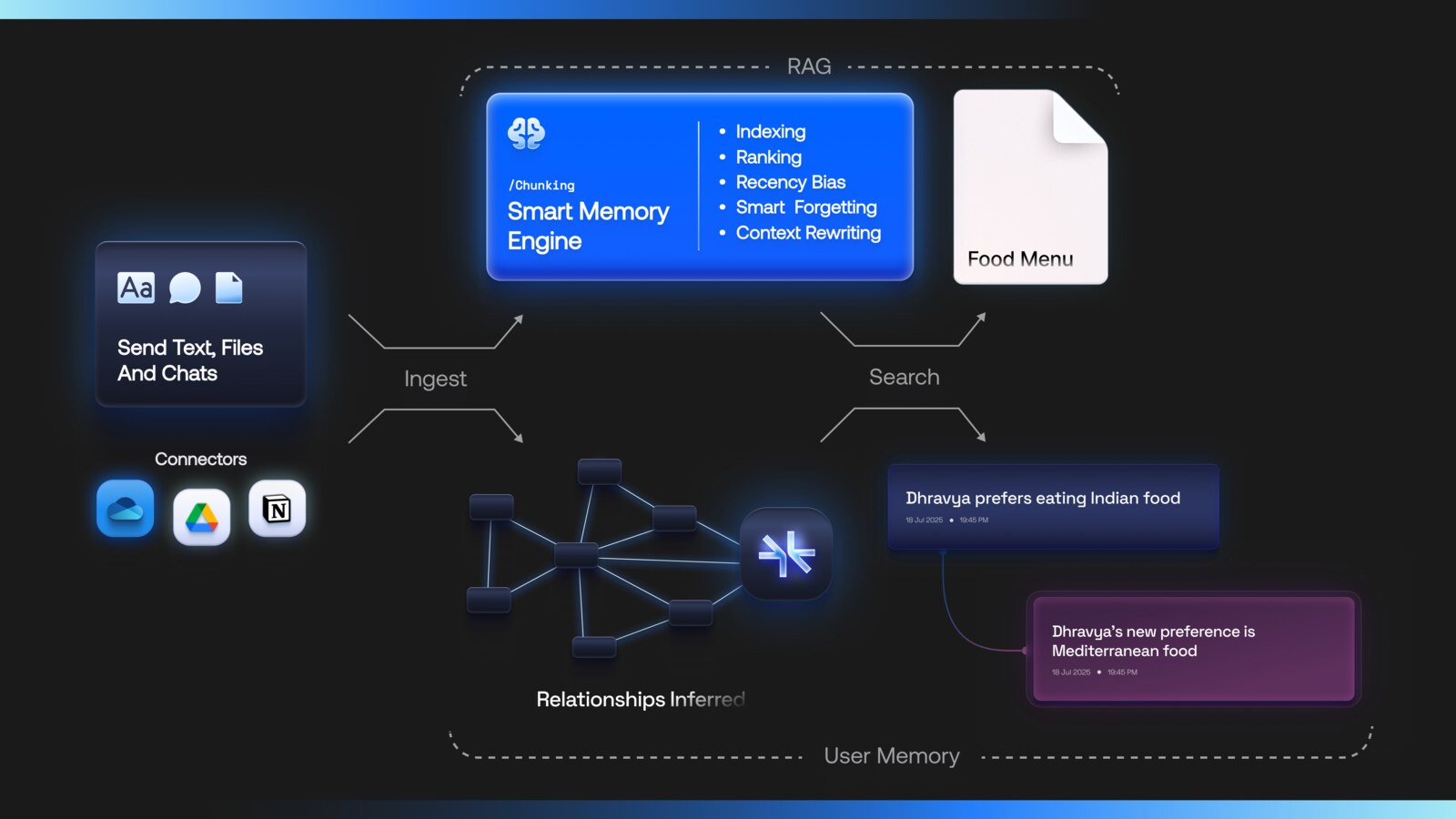
不只是 RAG,而是用户记忆和知识检索一起做
传统 RAG 更像是从文档里找片段,而 supermemory 关注的是“用户和上下文会随时间变化”这件事。它会从对话中抽取事实,处理偏好、项目状态、最近活动、知识更新和矛盾信息,也能让临时事实过期或被遗忘。
开发者可以通过一个 API 存储对话或内容,再用 profile/search 接口拿到用户画像和相关记忆。README 里的例子展示了 TypeScript 与 Python SDK:写入一段“用户偏好 TypeScript 和函数式模式”的内容后,就可以在后续请求里拿到长期事实、最近动态和相关 search results。
面向产品、Agent 和个人 AI 工具
supermemory 的应用面比较宽:对个人用户,它提供 App、浏览器扩展、插件和 MCP server,让 Claude Desktop、Cursor、Windsurf、VS Code、Claude Code、OpenCode、OpenClaw、Hermes 等客户端接入持久记忆;对开发者,它提供 memory、RAG、用户画像、连接器和文件处理能力。
连接器覆盖 Google Drive、Gmail、Notion、OneDrive、GitHub 和 Web Crawler;文件处理支持 PDF、图片 OCR、视频转录和代码 AST-aware chunking。框架集成方面,README 提到 Vercel AI SDK、LangChain、LangGraph、OpenAI Agents SDK、Mastra、Agno、Claude Memory Tool、n8n 等。
如果你在做 AI Agent、个性化助手、企业知识库或需要跨会话记忆的产品,supermemory 值得看。它把“存内容、抽记忆、建用户画像、混合检索、接外部数据源”这些上下文工程模块组合成了一套可直接调用的基础设施。
原创文章,如若转载,请注明出处:https://wefound.cc/p/4377.html