AI Agent 真正烧上下文的地方,往往不是最后那句问题,而是中间塞进去的工具输出、日志、检索片段、文件内容和历史对话。Headroom 想做的就是在这些内容进入模型之前先压缩一遍:README 里给出的定位很直接,目标是在答案质量不明显下降的前提下,把 Token 使用量压到原来的很小一部分。
它不是单一 SDK,而是一套可以放进不同工作流的上下文压缩层。你可以在 Python 或 TypeScript 里直接调用 compress(messages),也可以用 OpenAI-compatible proxy 做零代码接入;如果日常用 Claude Code、Codex、Cursor、Aider 这类 coding agent,还可以通过 headroom wrap 包一层。项目同时提供 MCP server,把 headroom_compress、headroom_retrieve 和统计能力暴露给 MCP 客户端。
比较有意思的是它强调可逆压缩。Headroom 会把原始内容留在本地,通过 CCR 机制让模型在需要细节时再取回,而不是把日志或检索内容一次性粗暴摘要掉。对经常调试线上事故、读长日志、做 RAG 或让 agent 大范围扫代码的人来说,这个方向比单纯“少放一点上下文”更实用,因为它保留了回溯细节的通道。
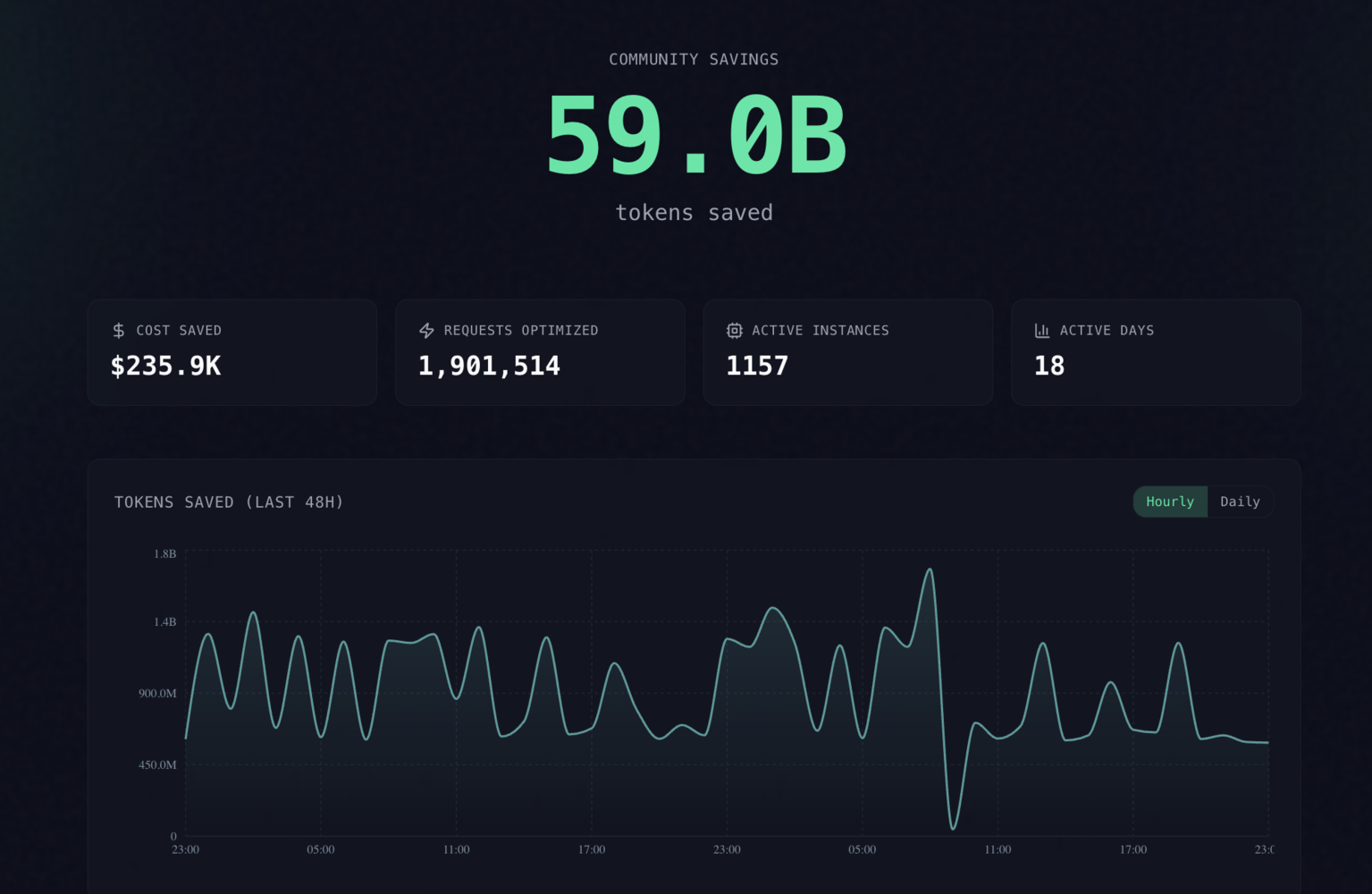
README 里展示的真实工作负载节省数据相当激进:代码搜索、SRE incident debugging、GitHub issue triage 等场景里,示例节省从 47% 到 92% 不等;项目也提供了 benchmark 和复现实验入口。它目前是 Apache-2.0 许可证,主语言是 Python,同时包含 Rust 和 TypeScript 代码,支持 pip、npm 和 Docker 安装。对于已经把 agent 放进日常开发流程的人,这类“上下文基础设施”可能比又一个聊天 UI 更值得关注。
项目地址
官网:https://headroom-docs.vercel.app/docs
项目地址:https://github.com/chopratejas/headroom
原创文章,如若转载,请注明出处:https://wefound.cc/p/4450.html