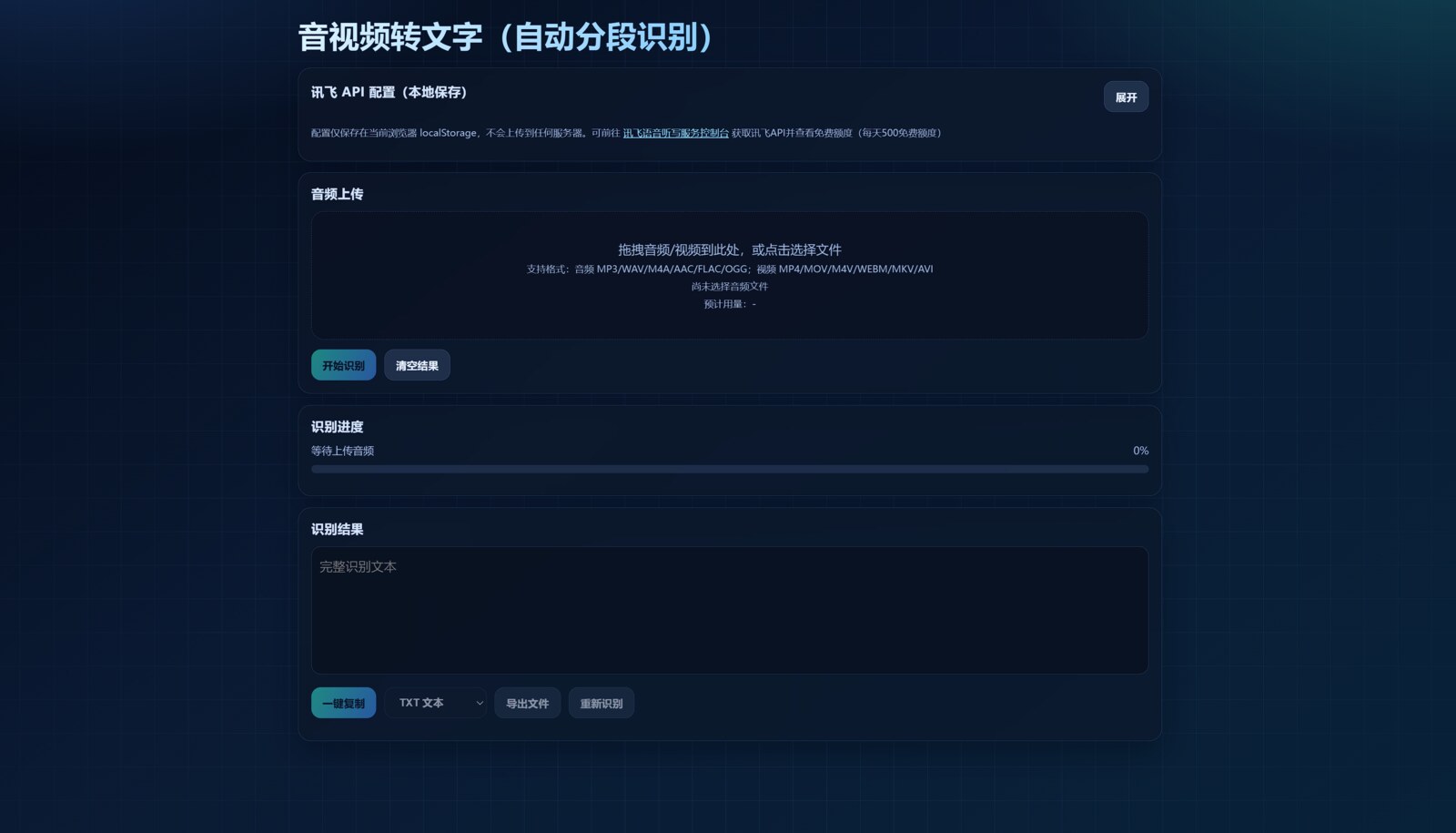
voice-to-text-tools 是一个纯前端的音视频转文字工具,适合把会议录音、访谈、课程音频或视频文件快速转成文本。它的特点是无需后端服务器,直接部署静态文件即可运行,核心识别能力来自讯飞语音听写 API。
项目支持上传音频和视频文件,并会自动做长音频分段处理,绕开单次语音识别时长限制。页面里填入 APPID、API Key、API Secret 后,就可以在浏览器端完成上传、分段、识别、复制和下载文本结果这套流程。
它的隐私边界需要讲清楚:所谓纯前端,是指项目本身不把配置上传到开发者自己的服务器,API Key 保存在浏览器 localStorage 中,也不需要额外后端中转。但语音识别本身仍然要调用讯飞接口,音频内容会进入对应的第三方识别服务,所以敏感录音不应直接丢进去处理。
技术上,这个项目由 HTML、CSS 和原生 JavaScript 构成,音频处理依赖 FFmpeg WebAssembly,语音识别走讯飞 WebSocket API。部署门槛很低:本地可以用 Python、PHP 或 Node 起一个静态服务,也可以放到 GitHub Pages、Cloudflare Pages 或任意静态托管平台。
README 里提到讯飞语音听写 API 每天有 500 次免费额度,对个人转写短音频、临时整理会议纪要或处理自媒体素材来说够用;如果是团队级、批量级使用,则需要关注接口额度、费用和识别准确率。
截至 2026 年 6 月 4 日,voice-to-text-tools 在 GitHub 上约有 30 stars,许可证为 MIT。它不是复杂的生产级转写平台,更像一个可以直接 Fork、改 UI、改部署方式的轻量工具模板。
原创文章,如若转载,请注明出处:https://wefound.cc/p/4666.html