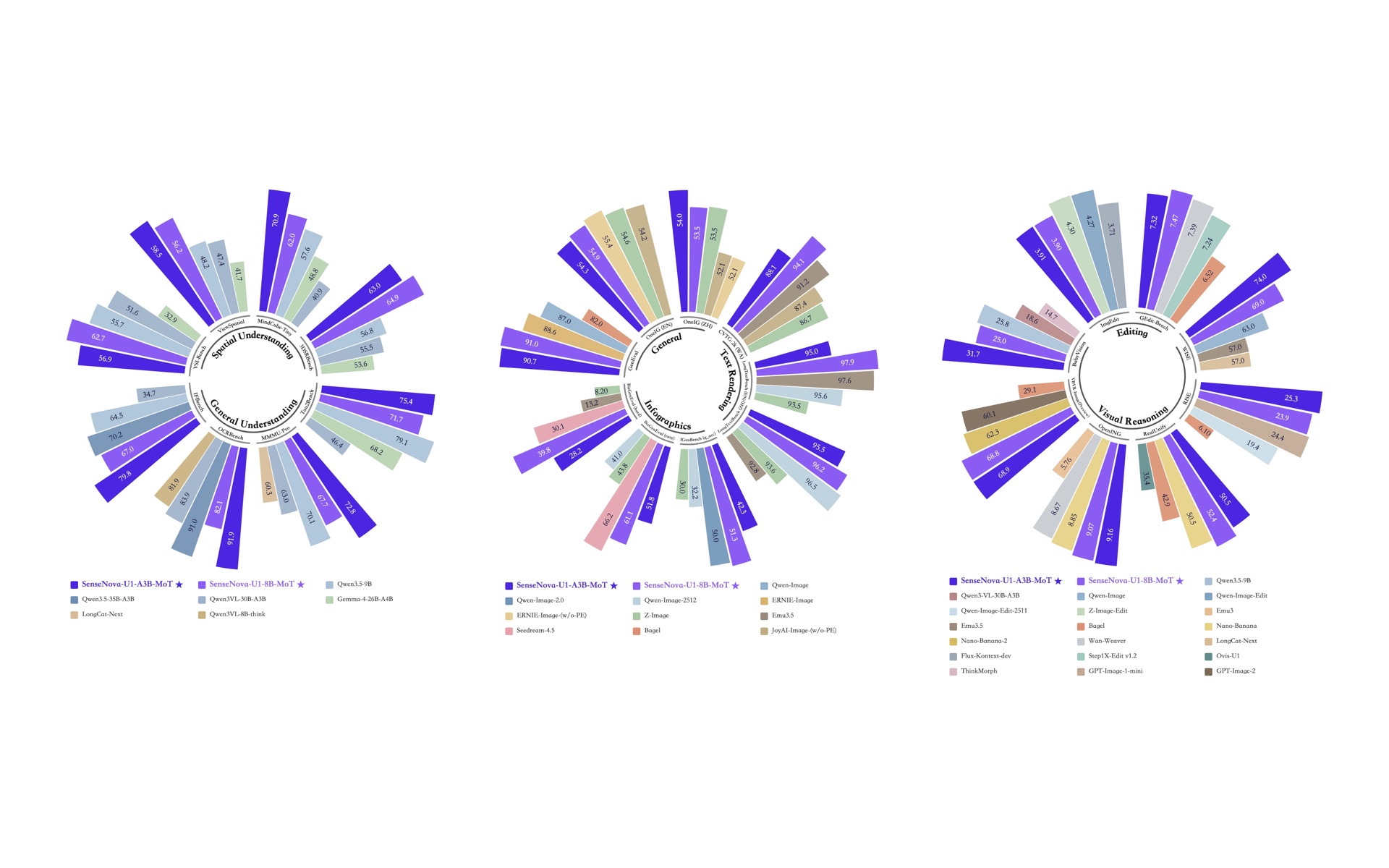
SenseNova-U1 是 OpenSenseNova 最新开源的一组统一多模态模型。它最有意思的地方,不是又多了一个“能看图、能生成图”的模型名,而是把视觉理解、推理、图像生成和图文交错生成放进同一套原生架构里处理。
截至 2026 年 5 月 18 日,这个仓库已经有 2.1k+ Star,并且仍在快速更新。项目采用 Apache-2.0 许可证,已经放出多组 8B / A3B MoT 模型、LoRA 8-step 版本、GGUF 转换和不同显存模式,入口覆盖 GitHub、Hugging Face、ModelScope 和 SenseNova Studio。
把看懂和生成放在同一张图里
传统多模态系统经常把理解和生成拆成几段:视觉编码器负责看图,另一个生成模块负责画图,中间再靠对齐和适配层衔接。SenseNova-U1 的路线更激进,它在 README 里强调 NEO-unify 原生统一范式,希望减少 VE / VAE 这类外挂式模块,让模型在同一个框架里完成理解、推理和生成。
这让它特别适合那些“既要读懂复杂视觉内容,又要继续生成内容”的任务,比如信息图理解、密集图文渲染、图文交错创作和多轮视觉推理。项目在 2026 年 5 月 15 日更新了面向高密度信息图的 SenseNova-U1-8B-MoT-Infographic,也把这条方向摆得很清楚:它不是只想做漂亮图,而是想让模型更好处理图表、文字和布局密集的视觉材料。
开放的不只是权重
目前仓库里列出的模型包括 SenseNova-U1-8B-MoT-Infographic、8B-MoT-SFT、8B-MoT、LoRA 8step,以及 A3B-MoT-SFT 和 A3B-MoT 等版本。官方还给了多条使用路径:可以在 SenseNova Studio 里直接试,也可以从 Hugging Face 或 ModelScope 拉取模型;想接入 agent 工作流,还能看 SenseNova-Skills 和 OpenClaw。
推理侧也有工程化痕迹。README 提到 LightLLM + LightX2V 的组合,在 H100 / H200 上生成 2048×2048 图片大约 9 秒左右,并且提供低显存模式与 GGUF 版本。对开发者来说,这比单纯放一张效果图更有价值,因为它给了从体验、下载到部署的连续路径。
它还没有假装自己完美
项目文档也把限制写得比较直接:上下文长度为 32K,人物相关生成细节、文字渲染拼写和格式稳定性仍可能出错,图文交错生成也还处在 beta 阶段。换句话说,它已经很适合拿来研究统一多模态路线、做原型验证或接入实验性工作流,但还不该被当成“什么视觉任务都稳定”的万能模型。
WeFound 关注它,是因为这个项目同时踩中了两个趋势:一个是开源多模态模型继续追赶闭源体验,另一个是“理解 + 生成 + agent 工具链”开始从演示走向可部署。SenseNova-U1 现在还在快速迭代,后续值得看它在复杂文档、信息图和真实产品流程里的表现。
项目地址
Hugging Face:https://huggingface.co/collections/sensenova/sensenova-u1
项目地址:https://github.com/OpenSenseNova/SenseNova-U1
原创文章,如若转载,请注明出处:https://wefound.cc/p/2731.html