很多时候,我们对 AI coding agent 的期待不是「改一个 bug」这么简单,而是更像一句宽泛的愿望:让测试跑得更快、让构建更轻、让查询延迟降下来、把 Lighthouse 分数往上推。难点在于,这类目标如果没有稳定指标,很容易变成凭感觉试几次,改了什么、为什么保留、为什么放弃,下一轮又该从哪里继续,都会散掉。
Codex Autoresearch 是 TheGreenCedar 做的一个 Codex 插件,专门处理这种「有目标、有 benchmark、有很多可尝试路径」的优化工作。它把一次优化拆成一个个小的 experiment packet:提出假设,做有限范围的修改,跑 benchmark 和 checks,用证据决定 keep、discard、crash 或 checks_failed,再把结果写进可恢复的 session 文件。
把“让它变好”变成可回放流程
README 里给出的典型场景很直观:测试耗时、构建速度、bundle size、模型 loss、Lighthouse 分数、内存使用、查询延迟,只要能从脚本里打印成指标,就可以纳入循环。用户需要给 Codex 一个目标、benchmark contract 和安全编辑范围,插件会帮助 Codex 做 onboard、setup、doctor、dashboard、packet、log、continue 或 finalize 这一套流程。
它比较有意思的一点是 ASI,也就是 Accumulated Structured Intelligence。你可以把它理解成每轮实验留下来的结构化记忆:假设是什么,证据是什么,为什么回滚,下轮有什么提示,属于哪条策略 lane、风险或 family。对长任务来说,这比单纯的聊天上下文可靠,因为即使上下文丢失,后续 Codex 也能沿着 ledger 和 ASI 继续判断。
适合有明确指标的代码库
Codex Autoresearch 不适合所有任务。它真正擅长的是「可以量化」的目标:benchmark 可重复,correctness checks 存在或可以补上,编辑范围足够小,最终留下的工作需要变成可 review 的 commits 或 branches。反过来,如果任务主要靠审美、判断,或者 benchmark 很贵、很不稳定,就不如让 Codex 做一次普通的精细修改。
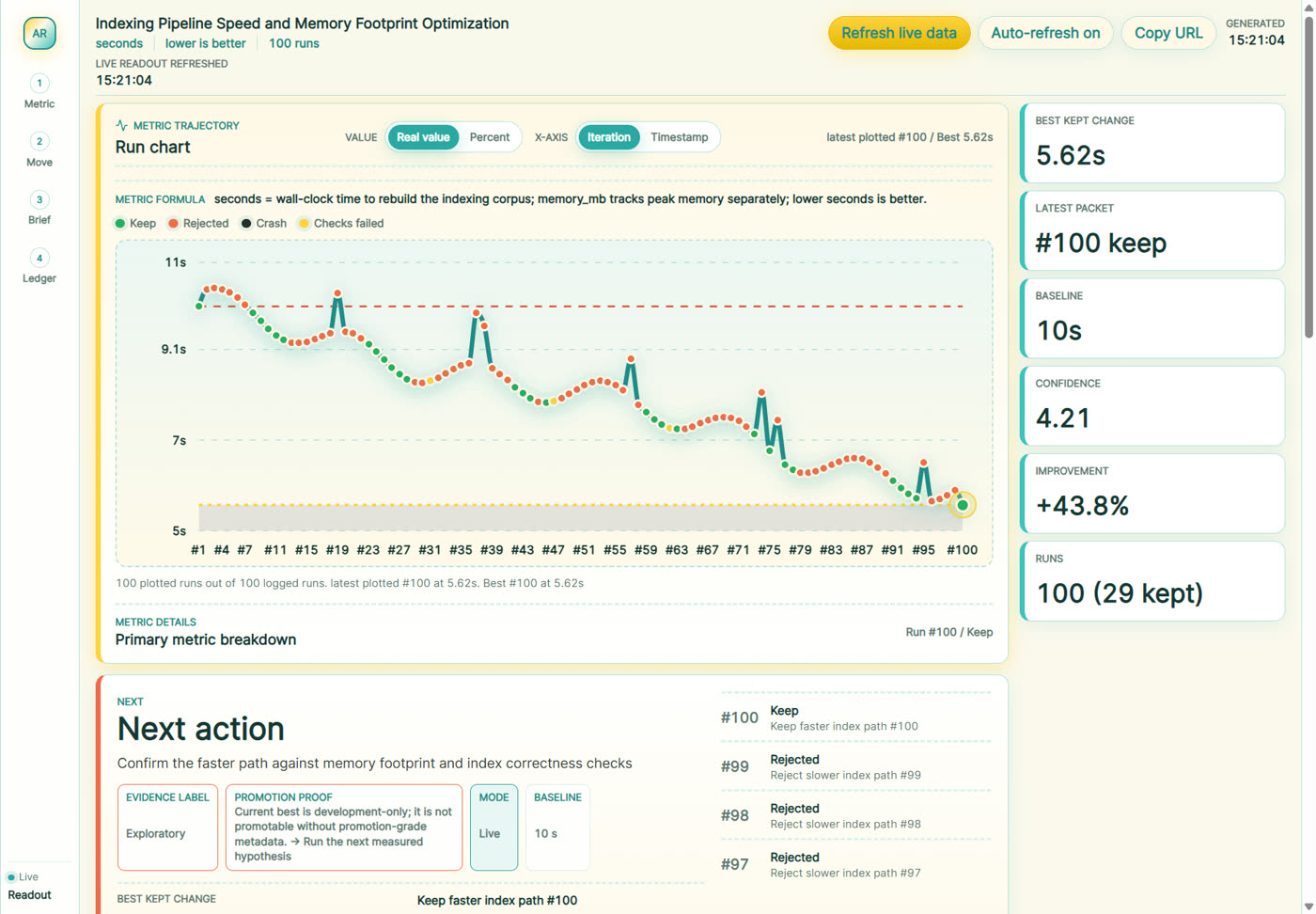
项目还带一个 dashboard,用来展示 baseline、latest、best、confidence、weighted metric、ledger entries、proof gaps、best kept change 和 recent failures。截图里的演示是索引管线速度与内存占用优化:100 次运行里记录 keep/rejected/crash/checks failed,最终展示 best kept change、baseline、confidence 和 improvement。这种界面对人类 reviewer 很友好,因为它把 agent 的试错过程摊开了。
安装方式也保持在 Codex 插件体系里:先添加 marketplace,再在目标代码库里通过 /plugins 安装。仓库当前约 530 stars,Apache-2.0 许可证,最新 release 是 2026 年 5 月 16 日发布的 v1.3.6。它不是一个“自动让项目变神”的按钮,更像是给 Codex 加了一套科研记录本和实验仪表盘:每一步都要有指标、有证据、有边界。
项目地址
项目地址:https://github.com/TheGreenCedar/codex-autoresearch
原创文章,如若转载,请注明出处:https://wefound.cc/p/2741.html