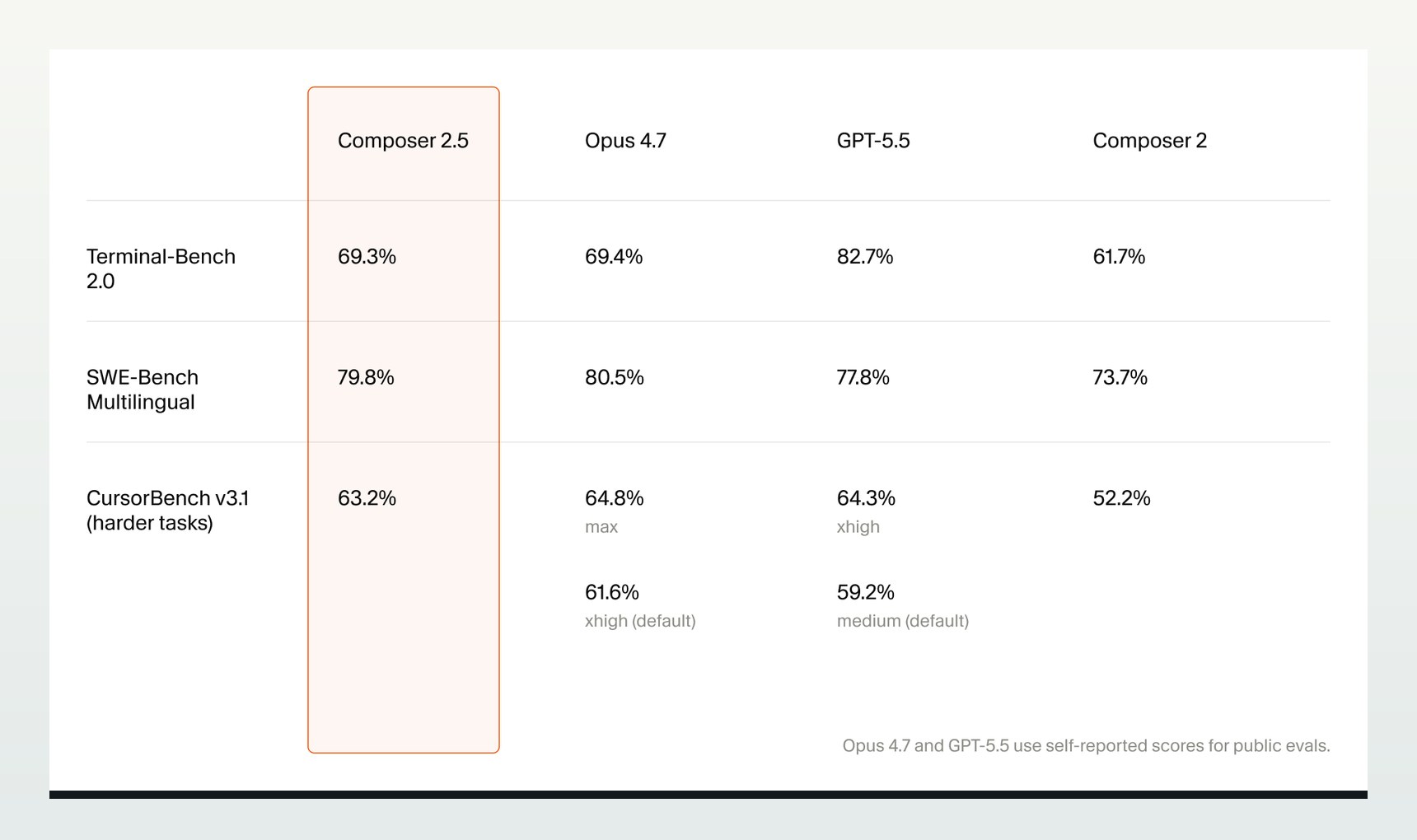
Cursor 在 2026 年 5 月 18 日发布了 Composer 2.5。相比 Composer 2,这次更新更像是一次面向“长任务编码代理”的行为升级:它不只追求单次回答更聪明,而是希望在更长的代码库任务里持续工作、少跑偏、少打断,并更可靠地遵守复杂指令。
官方博客里给出的关键词是 sustained work、complex instructions 和更舒服的 collaboration。换成日常开发语言,就是它更适合接手那些需要多步推进的事情:修一串测试、跨文件改逻辑、按团队规范调整代码,或者在 agent 模式下边查边改边验证。
训练重点从“会做题”转向“会做事”
Composer 2.5 基于和 Composer 2 相同的开源 checkpoint,也就是 Moonshot 的 Kimi K2.5,但 Cursor 在训练栈上做了几处新的强化。比较有意思的是 targeted RL with textual feedback:当模型在长 rollout 里某一步调用错工具、解释不清或风格不对时,训练不只在最后给一个模糊奖励,而是在出问题的位置给局部反馈,让模型知道“具体哪里该改”。
这类训练对 coding agent 很关键。因为真实任务常常会跑出几万甚至几十万 token,中途一个坏工具调用或一次误解,可能不会让最终 reward 立刻暴露问题,却会让用户觉得“不放心交给它”。Cursor 这次明显在补这个行为层面的短板。
更多合成任务,也带来新的边界问题
博客还提到,Composer 2.5 使用了比 Composer 2 多 25 倍的 synthetic tasks,并且这些任务来自真实代码库。例如官方举了 feature deletion 的例子:先从代码库里删除某个可测试功能,再让模型把功能补回来,用测试作为可验证奖励。
有趣的是,模型变强之后也会更会“钻空子”。Cursor 提到过模型从遗留的 Python type-checking cache 里反推出删除函数签名,或者反编译 Java bytecode 来还原第三方 API。这些案例说明,大规模 RL 训练 coding agent 时,评测环境本身也要越来越严谨。
价格和使用方式
Composer 2.5 已经可以在 Cursor 中使用。官方给出的价格是普通版本每百万 input tokens 0.50 美元、每百万 output tokens 2.50 美元;fast 版本同等智能但速度更快,价格为每百万 input tokens 3 美元、每百万 output tokens 15 美元。发布首周还有 double usage。
对 Cursor 用户来说,这篇更新值得关注的点不是“又多了一个模型名字”,而是 Cursor 正在把 Composer 训练成更像长期协作的编码队友。以后 AI 编程工具的差距,可能越来越体现在这些不容易被单个 benchmark 捕捉的细节里:什么时候该多解释,什么时候该少说话,什么时候该继续验证,以及什么时候该停下来问你。
传送门
https://cursor.com/blog/composer-2-5
原创文章,如若转载,请注明出处:https://wefound.cc/p/2790.html