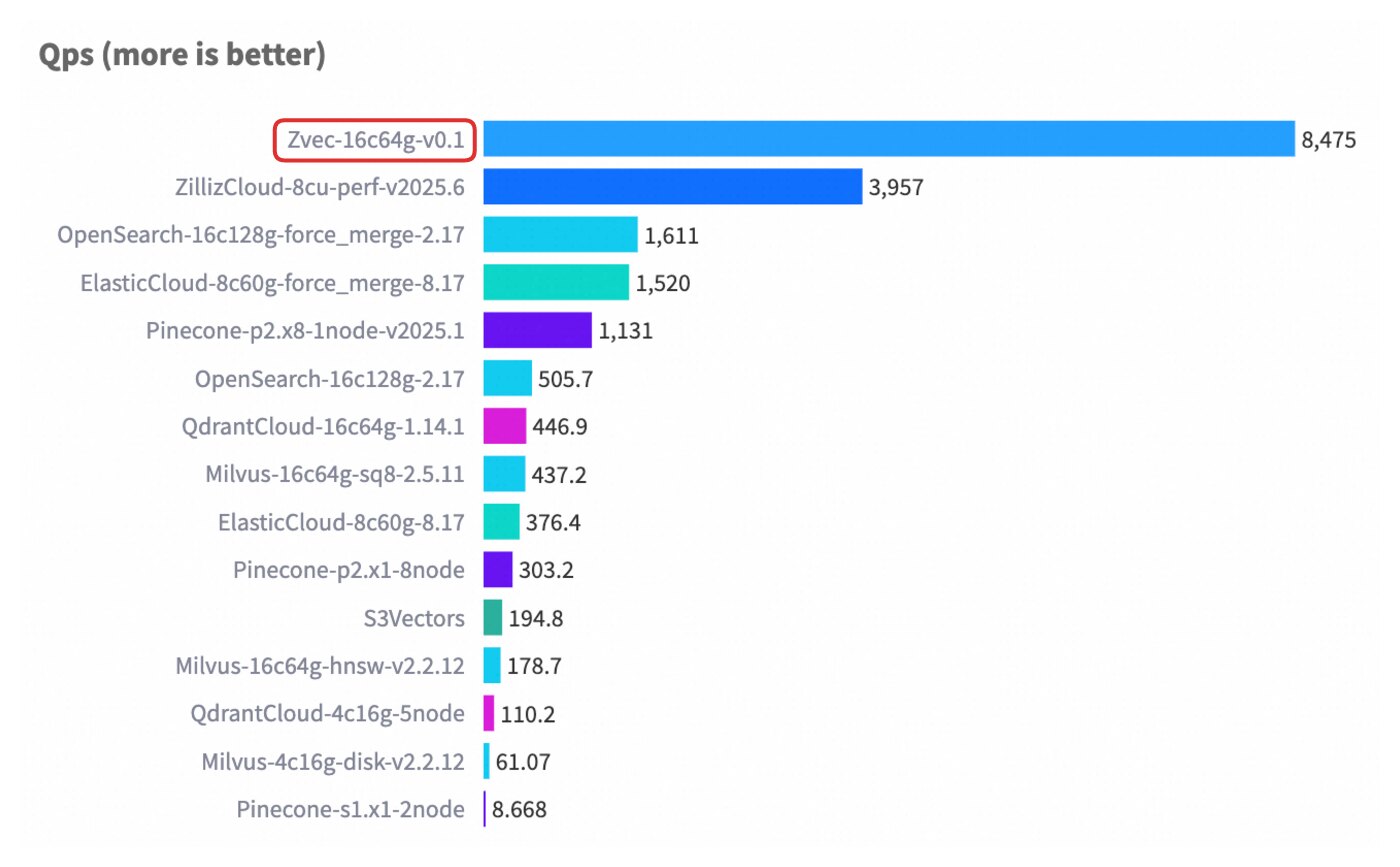
如果你正在给 RAG、语义搜索或本地 AI 应用补一层向量检索,Zvec 的思路很直接:不再把向量数据库当成一套单独服务去部署,而是把它作为进程内库嵌进应用。它由阿里开源,项目描述是 lightweight、lightning-fast、in-process vector database,主仓库当前约 9.7k stars,许可证为 Apache-2.0。
这类设计的价值在于少了一层运维和网络调用。Zvec 可以在 notebook、服务端、CLI 工具甚至边缘设备里直接运行,README 里强调“纯本地、无需服务器、无需配置”。对于原型验证、小型知识库、离线检索、需要低延迟的应用内搜索来说,这种形态会比先拉起一整套外部数据库轻很多。
它更像一块可嵌入的检索引擎
Zvec 支持稠密向量和稀疏向量,也支持混合检索:语义相似度可以和结构化过滤条件一起用,适合做文档召回、代码搜索、推荐、记忆库这类场景。它还带 WAL 持久化,目标不是只做内存里的临时索引,而是给应用提供能落盘、能恢复的本地向量存储。
开发者入口也比较友好。官方包已经覆盖 Python 和 Node.js,README 给出的 Python 示例从 collection schema、插入文档到 query 都是一分钟级别;最新 v0.4.0 还加入了 Dart/Flutter SDK 与 iOS 构建支持,说明项目正在往移动端和跨平台嵌入继续扩展。
需要注意的是,进程内数据库并不等于所有场景都该替换成它。Zvec 更适合你希望把检索能力贴近应用、减少部署负担、追求本地低延迟的工作流;如果团队已经需要多租户、集中运维、复杂权限和大规模集群管理,仍然要把它和服务化向量数据库放在同一张架构图里比较。
项目地址
官网:https://zvec.org
项目地址:https://github.com/alibaba/zvec
原创文章,如若转载,请注明出处:https://wefound.cc/p/3429.html




