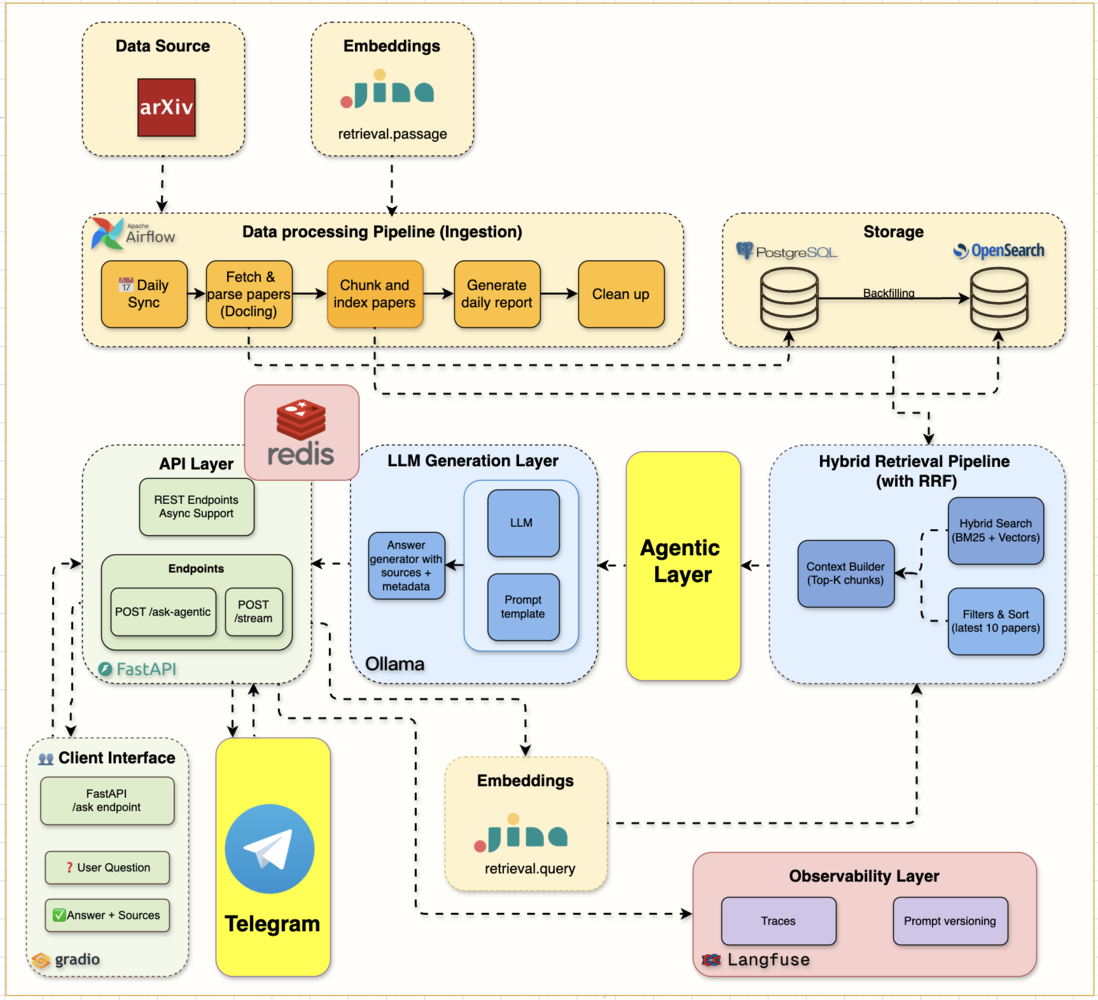
Production Agentic RAG Course 是一个围绕“arXiv Paper Curator”搭起来的实战课程仓库。它不是只演示一个向量数据库接 LLM 的小 demo,而是把 RAG 系统按周拆成可运行的工程:从基础设施、数据摄取、BM25 搜索,到 chunking、hybrid retrieval、完整 RAG pipeline,再到监控、缓存和 Agentic RAG。
这个课程有一个很实用的观点:生产 RAG 不是一上来就向量搜索,而是先把 keyword search、过滤、相关性评分和数据管道打牢,再叠加语义检索。前几周会用 Docker Compose、FastAPI、PostgreSQL、OpenSearch、Airflow、Ollama 等组件搭基础设施,并从 arXiv 抓取论文、解析 PDF、写入数据库和搜索索引。
后面的内容逐步升级:Week 4 做 chunking 和 hybrid search,Week 5 接完整 RAG 和 Gradio 界面,Week 6 加 Langfuse tracing 与 Redis caching,Week 7 则用 LangGraph 做 Agentic RAG,加上文档相关性评估、查询改写、越界问题 guardrails,以及 Telegram bot 移动端入口。对想把 RAG 做到可观测、可调试、可迭代的人来说,这种路线比单篇教程更接近真实工程。
仓库目前有 6.2k+ Star,MIT 许可证,主语言是 Python,也包含 Jupyter Notebook、Dockerfile 和 Makefile。它需要 Python 3.12+、Docker Desktop、UV,并建议准备 8GB+ 内存和 20GB+ 磁盘空间;这也说明它面向的是愿意完整搭环境、跑服务、看 trace 的学习者,而不是只想复制一段 prompt 的读者。
传送门
https://github.com/jamwithai/production-agentic-rag-course
原创文章,如若转载,请注明出处:https://wefound.cc/p/4466.html