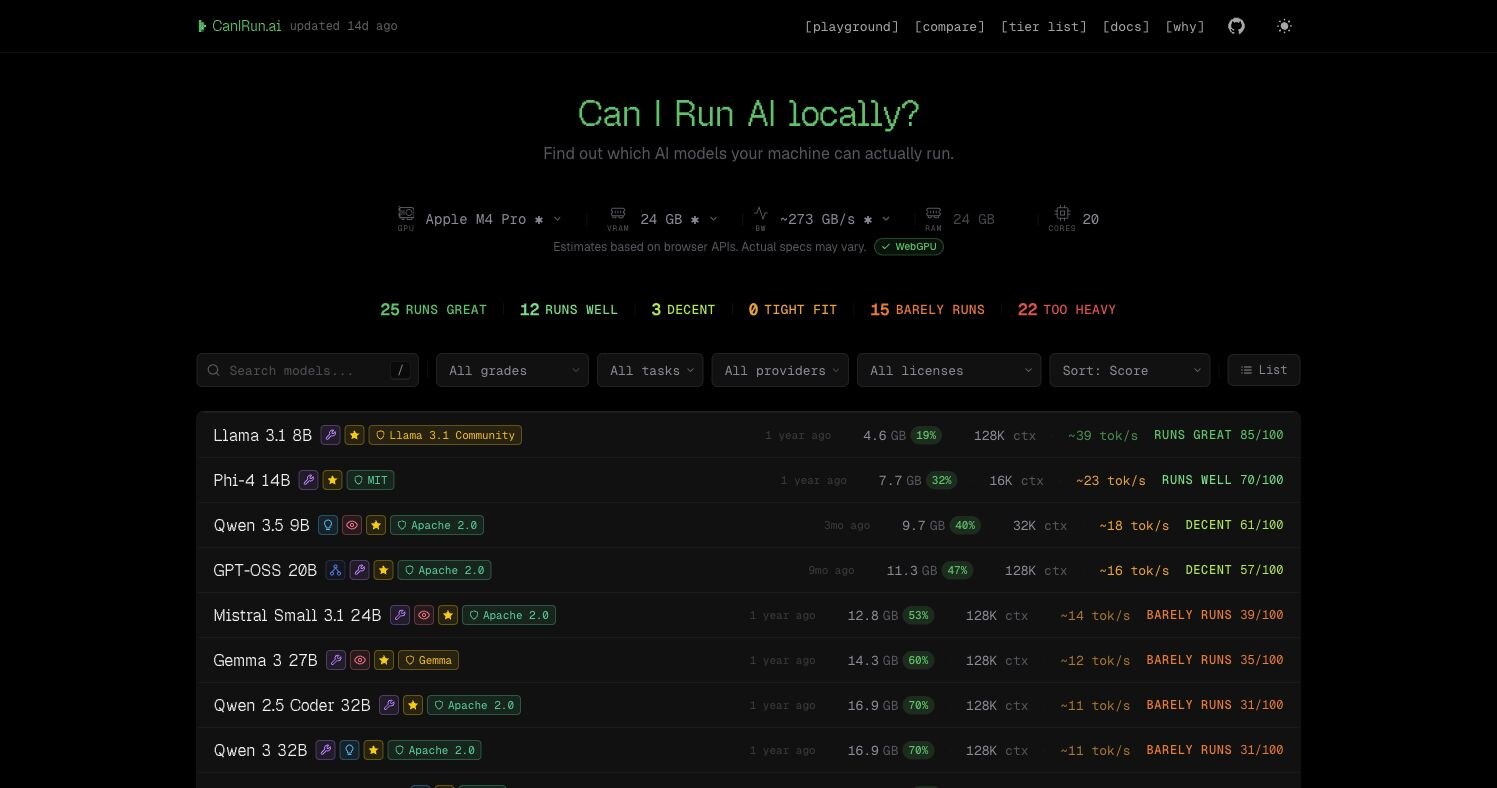
CanIRun.ai 是一个很直接的在线工具:打开网页后,它会通过浏览器 API 估算你的 GPU、VRAM、系统内存、带宽和核心数,然后告诉你这台机器大概能跑哪些本地 AI 模型。页面会把模型按 RUNS GREAT、RUNS WELL、DECENT、TIGHT FIT、BARELY RUNS、TOO HEAVY 这类状态分组,给一个比“看参数猜显存”更快的初筛。
它适合想尝试本地大模型但不想翻一堆 VRAM 表格的人。比如你只想知道自己的 Mac、笔记本 GPU 或桌面显卡能不能跑 Qwen、Llama、Gemma、Phi、Mistral 这类模型,CanIRun.ai 会把模型参数量、量化版本、显存占用、上下文长度、许可证和预估速度放在同一张列表里。
页面还提供筛选和排序:可以按模型等级、任务类型、Provider、License 来过滤,也能在 playground、compare、tier list、docs 之间切换。对开发者来说,它的价值不是给出绝对性能承诺,而是把“我应该先下载哪个模型试试”这件事变成几分钟内能判断的选择题。
需要注意的是,浏览器侧硬件检测本身就是估算,页面也明确提示实际规格可能有偏差。尤其是 Apple Silicon、核显、共享内存或浏览器无法完整读取 GPU 信息时,结果更适合做初筛,不应该替代真实 benchmark。稳妥做法是用它缩小候选范围,再用 Ollama、llama.cpp 或 LM Studio 实测自己常用的量化版本。
如果你经常在“模型太大跑不动”和“模型太小效果不够”之间摇摆,这种工具很省时间。它把硬件、模型、许可证和速度预估放在一个界面里,让本地 AI 的第一步少一点玄学。
传送门
原创文章,如若转载,请注明出处:https://wefound.cc/p/4494.html