Voice-Pro 是一个面向创作者和开发者的 AI 音频/配音 WebUI。它把 YouTube 下载、音频提取、人声分离、语音识别、字幕生成、翻译、TTS 和声音克隆放在同一个 Gradio 界面里,目标是把“拿到一段视频或音频,再做多语言配音/字幕”的流程尽量串起来。
它的技术栈相当豪华:语音识别侧包含 Whisper、Faster-Whisper、Whisper-Timestamped 和 WhisperX;TTS 侧有 Edge-TTS、kokoro,以及 E2-TTS、F5-TTS、CosyVoice 这类零样本声音克隆方案;视频和音频处理则接入 yt-dlp、ffmpeg、Demucs、MDX-Net 等工具。README 里也把它定位成面向 podcast、开发者、创作者和多语言专业用户的 ElevenLabs 替代思路。
适合把配音流程跑通的人
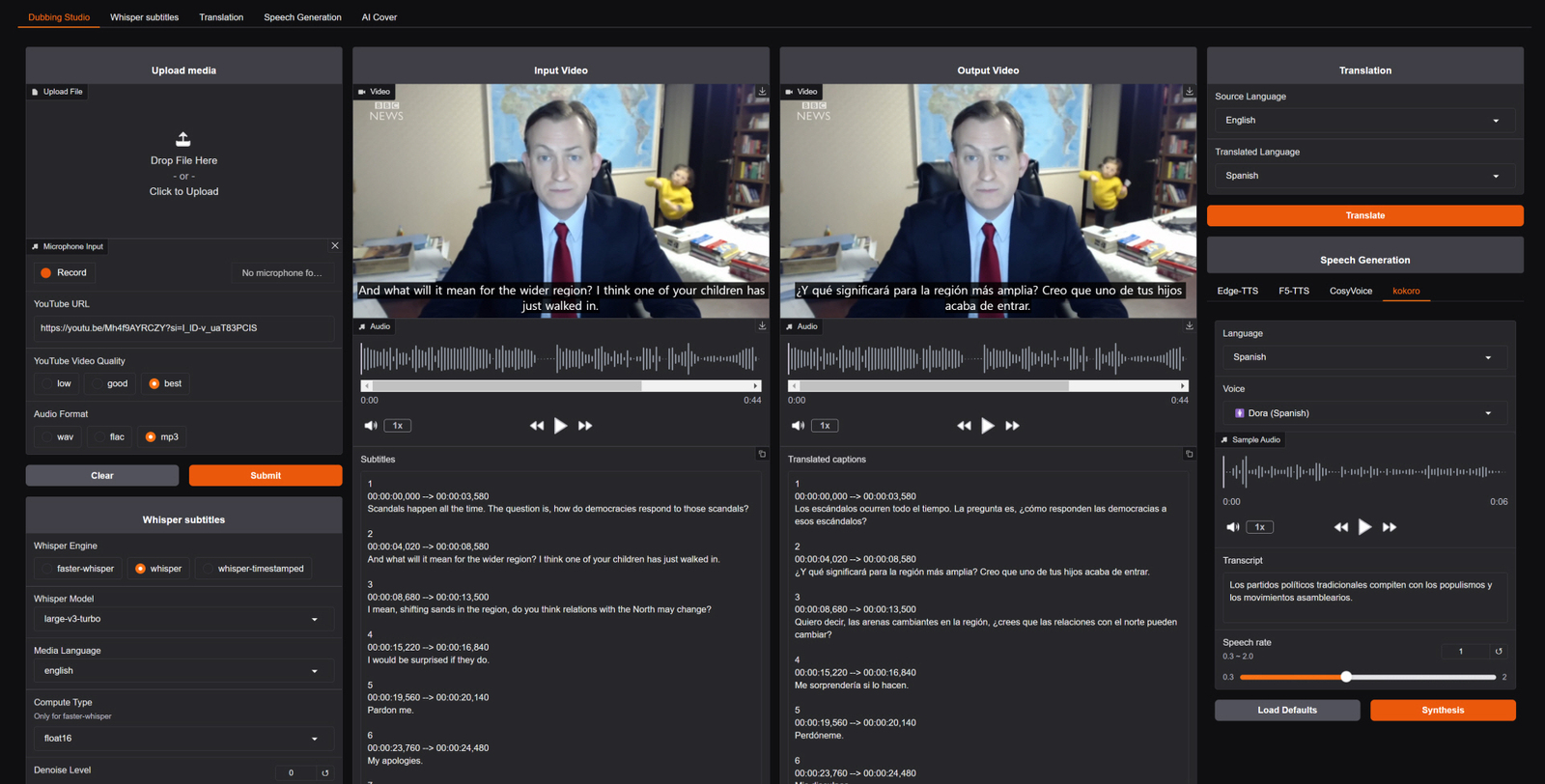
从截图看,Voice-Pro 的 Dubbing Studio 会把输入视频、输出视频、波形、字幕、翻译结果和右侧的语音生成设置放在同一页。你可以上传媒体或填 YouTube URL,选择 Whisper 引擎和模型,再把识别文本翻译成目标语言,最后用 Edge-TTS、F5-TTS、CosyVoice 或 kokoro 生成新的语音。
这类工具最有用的场景,不是单独炫一个模型,而是把多个模型和传统音视频工具接成流水线。比如给公开视频做字幕和多语言配音、把采访转写后翻译、尝试用参考音色生成不同语言版本,或者在本机 GPU 上搭建一个可调参数的配音实验台。
先看限制,再决定要不要装
Voice-Pro 最近一次 release 是 v3.2.0,仓库约 9700+ Star,主要语言是 Python,LICENSE 文件为 GPL-3.0。README 也写得很直白:作者因为转向 WeConnect 开发,Voice-Pro 近期暂时无法继续维护;它在 Windows + NVIDIA GPU 上运行较好,Mac 和 Linux 虽然 v3.2 提到支持,但 README 的注意事项仍提示相关运行情况没有充分验证。
所以它更像一个已经开源出来的完整工作台,而不是持续商业化打磨中的云服务。如果你有 Windows/NVIDIA 环境,愿意处理模型下载、CUDA、ffmpeg 和 Python 依赖,它很值得试;如果你想要开箱即用、跨平台稳定、持续更新的成品工具,就需要对维护状态和安装成本多留一点余量。
传送门
https://github.com/abus-aikorea/voice-pro
原创文章,如若转载,请注明出处:https://wefound.cc/p/3339.html




