SpineDigest 是一个开源 CLI / TypeScript 库,目标是把长篇书籍压缩成“书脊”:不仅输出文本摘要,还会构建章节拓扑和知识图谱,让整本书的结构一眼可见。它支持 EPUB、Markdown、TXT 和自有的 .sdpub 格式,适合做深度阅读、资料压缩和 AI Agent 可调用的读书管线。
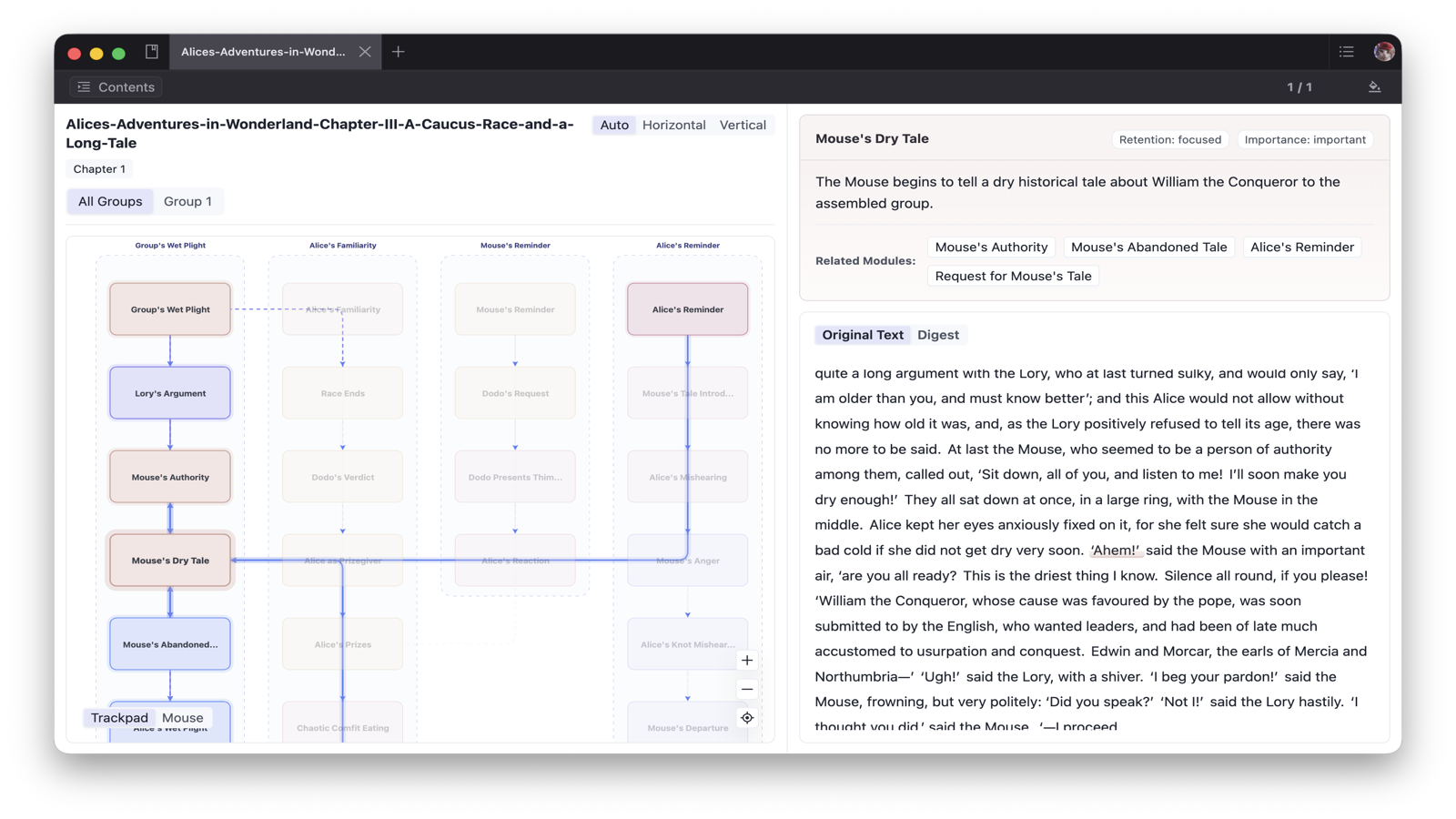
项目的核心思路不是简单把全文塞进上下文窗口,而是分阶段处理。第一步由 LLM 按章节读取并抽取 chunk,把原文拆成独立知识单元;第二步用传统图算法根据概念相关性连接节点、聚类,并形成按原始阅读顺序串联的 snake 知识链;最后再交给多 Agent 式的摘要阶段。
README 里把最后一步比作论文答辩:respondent 负责写摘要,多个 professor 分别拿着不同 snake 对草稿提出挑战,迫使最终摘要在用户设定目标下兼顾不同部分的内容。这也解释了为什么它支持 prompt 指定阅读意图,比如保留人物情绪变化、强调实践建议或提炼中心论点。
SpineDigest 每次处理后会生成 .sdpub 文件,里面保存摘要文本、chunks、snakes、完整概念图等结构数据。之后可以无 LLM 重新导出 EPUB、Markdown 或纯文本;如果想可视化浏览,则可以用 Inkora 打开 .sdpub 查看章节拓扑和知识图谱。
传送门
https://github.com/oomol-lab/spinedigest
原创文章,如若转载,请注明出处:https://wefound.cc/p/1983.html